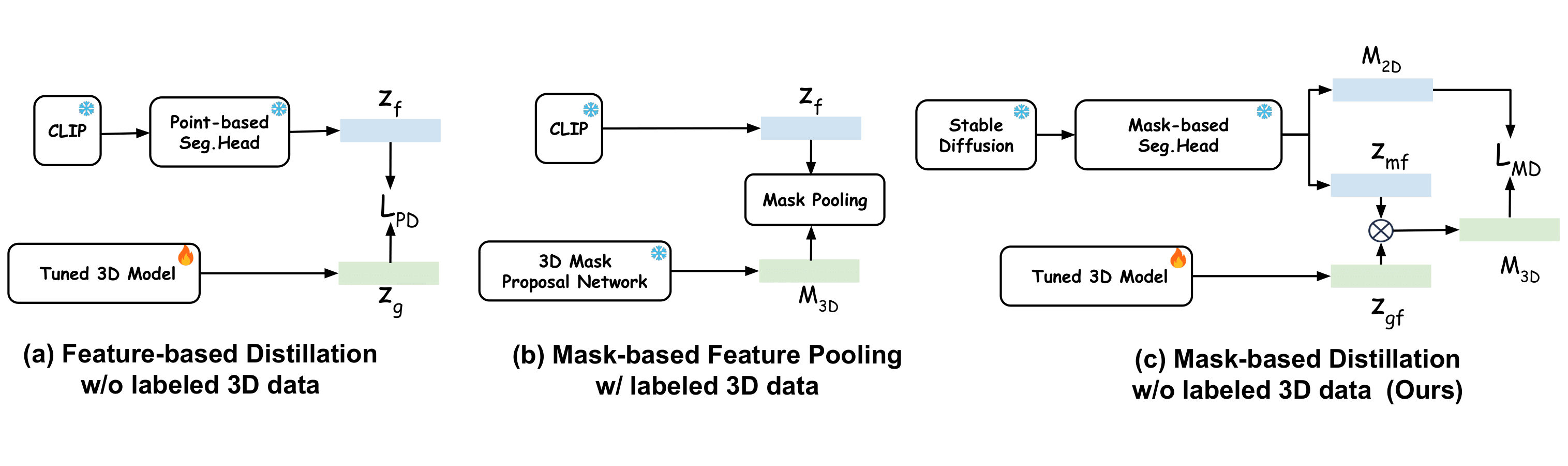
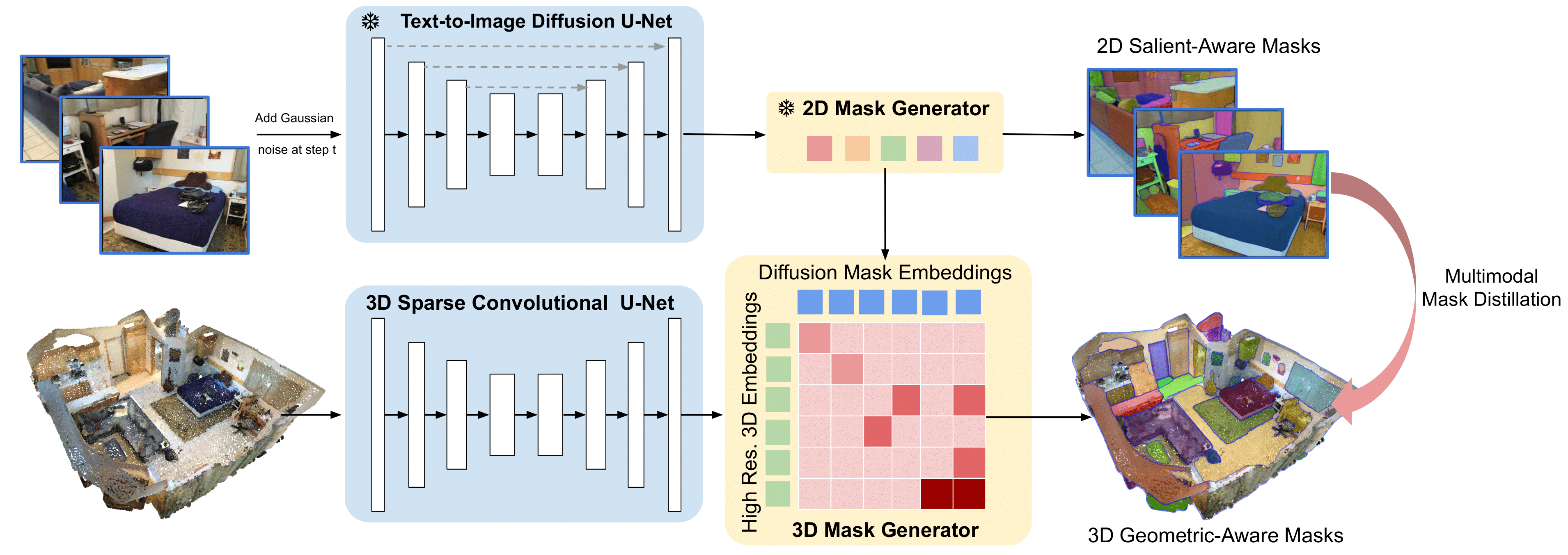
Open-Vocabulary 3D Perception-Problem Definition
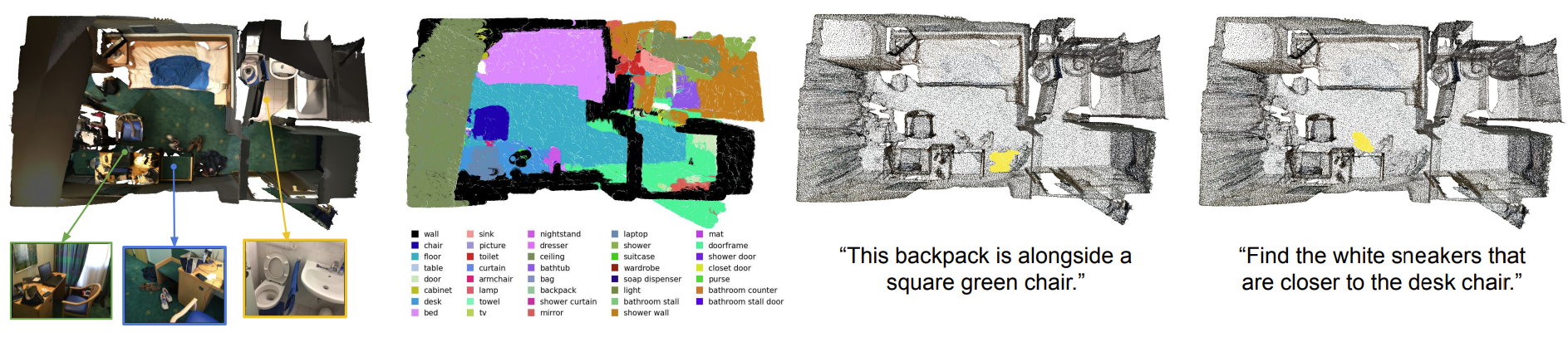
Illustration of open-vocabulary 3D semantic scene understanding. We propose Diff2Scene, a 3D model that performs open-vocabulary semantic segmentation and visual grounding tasks given novel text prompts, without relying on any annotated 3D data. By leveraging discriminative-based and generative-based 2D foundation models, Diff2Scene can handle a wide variety of novel text queries for both common and rare classes, like “desk” and “soap dispenser”. It can also handle compositional queries, such as “find the white sneakers that are closer to the desk chair.”